Ah, le crawling ! Tu sais, ce terme un peu technique qu'on entend souvent quand on parle de référencement et de moteurs de recherche ? C'est un peu comme une recette de grand-mère, pleine de secrets et de savoir-faire. Alors, comment ça s'appelle exactement, ce processus magique ? Accompagne-moi, je vais te l'expliquer autour d'un café.
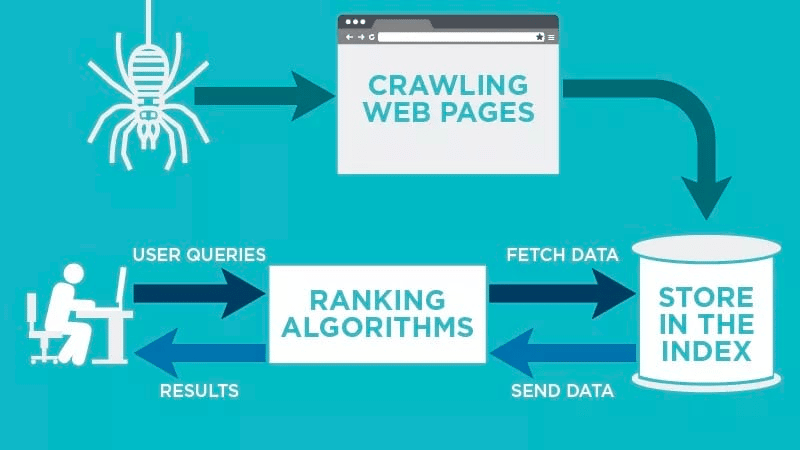
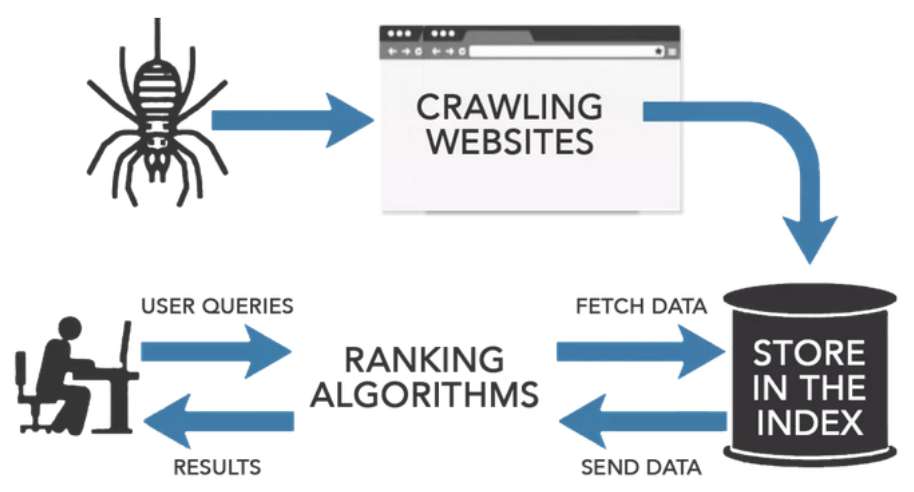
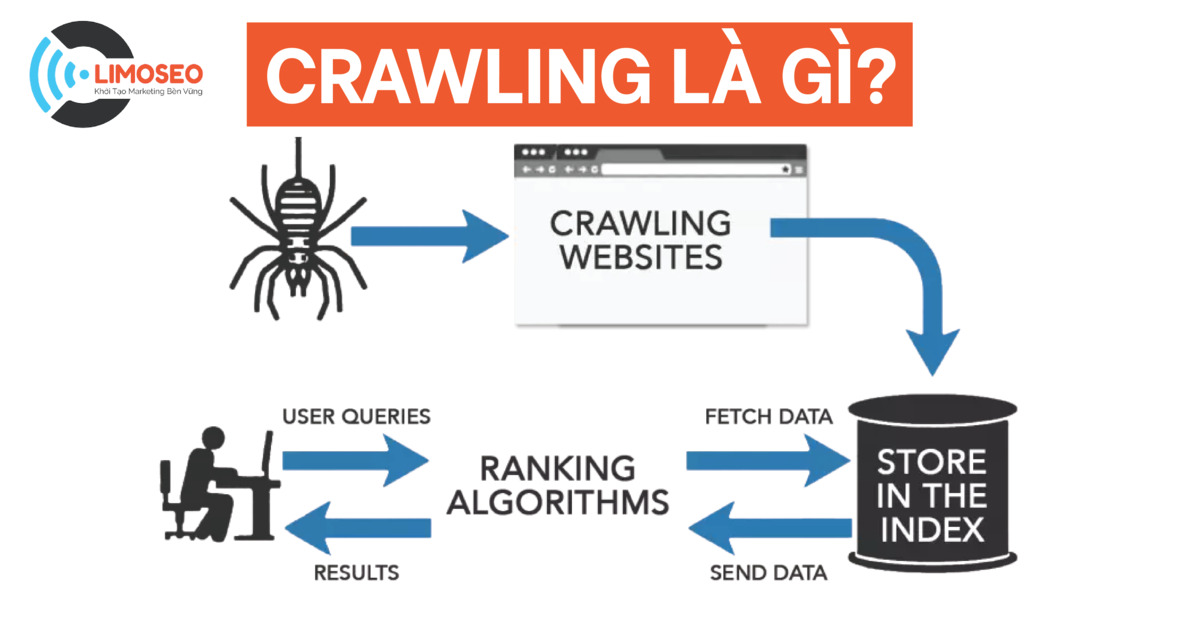
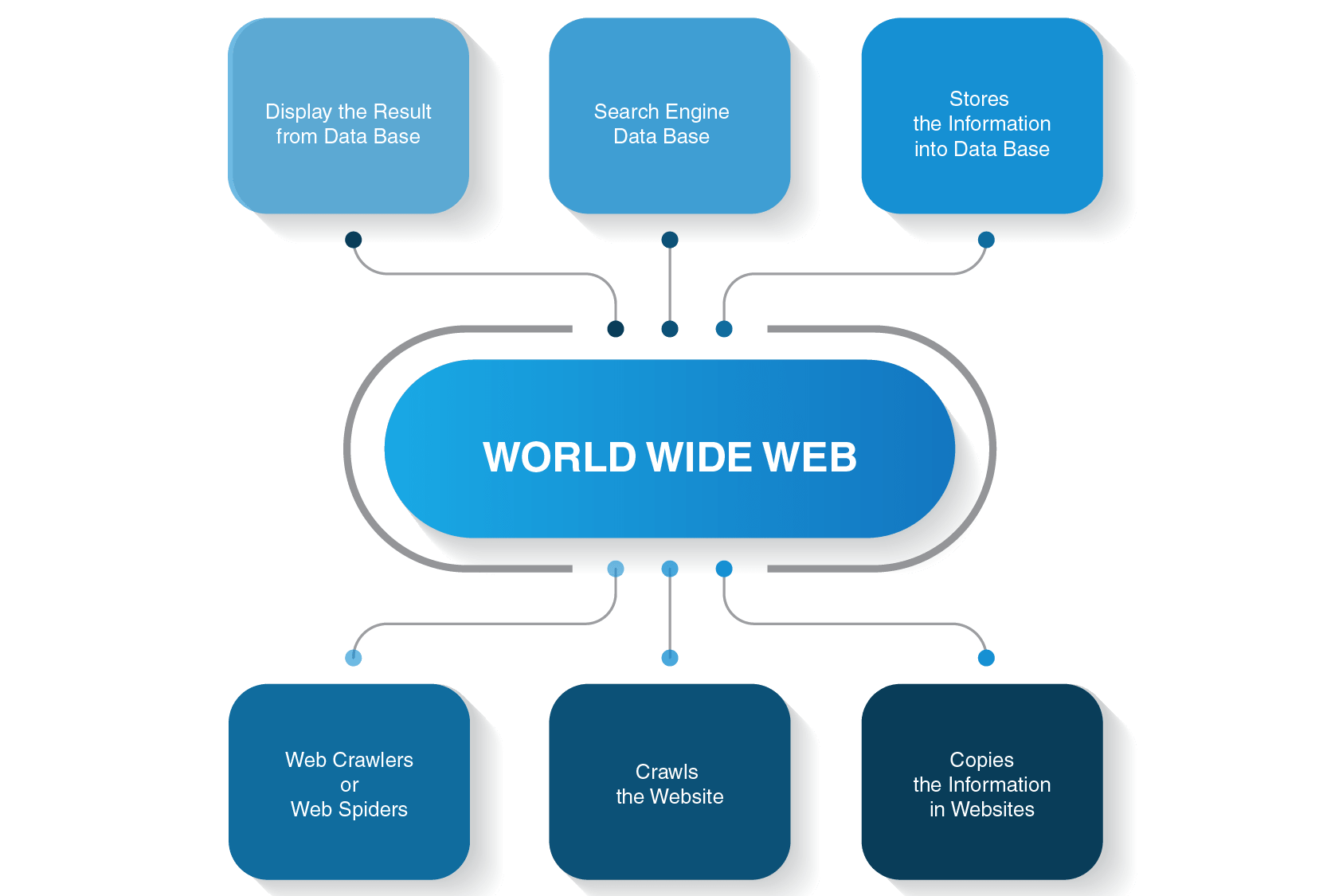
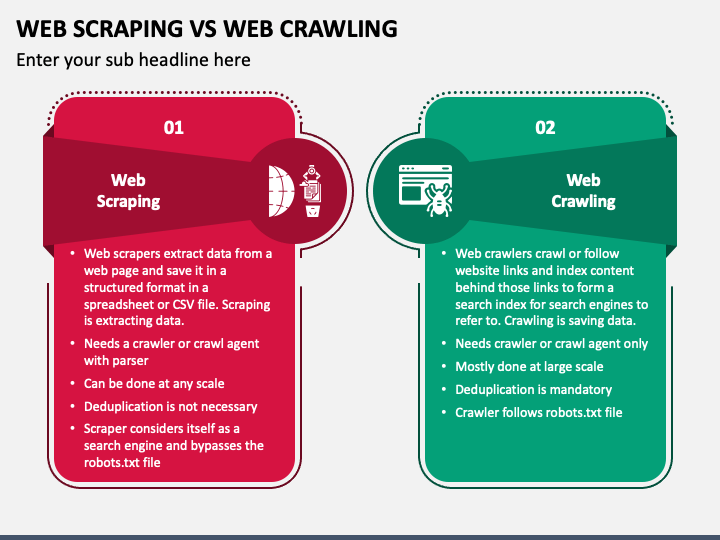
Le crawling, en français, on l'appelle l'exploration du web ou encore, plus simplement, le crawl. C'est le petit nom qu'on lui donne dans le milieu. Imagine un petit robot (ou plutôt un logiciel très sophistiqué) qui parcourt le web de lien en lien. Tu vois l'image ?
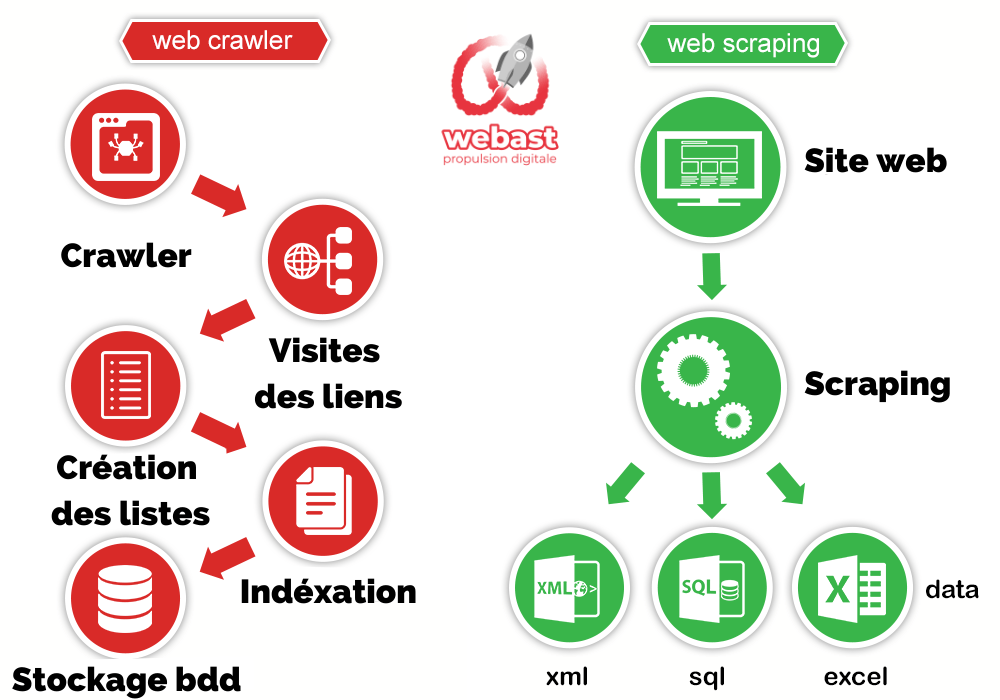
Ce robot, qu'on appelle aussi un crawler, un spider (araignée) ou encore un bot, suit les liens hypertextes qui relient les pages web entre elles. C'est un peu comme suivre une piste de miettes de pain, sauf que les miettes sont des liens et la forêt, c'est l'immensité du web ! C'est fascinant, non ?
Mais, à quoi ça sert, exactement, d'explorer le web ?
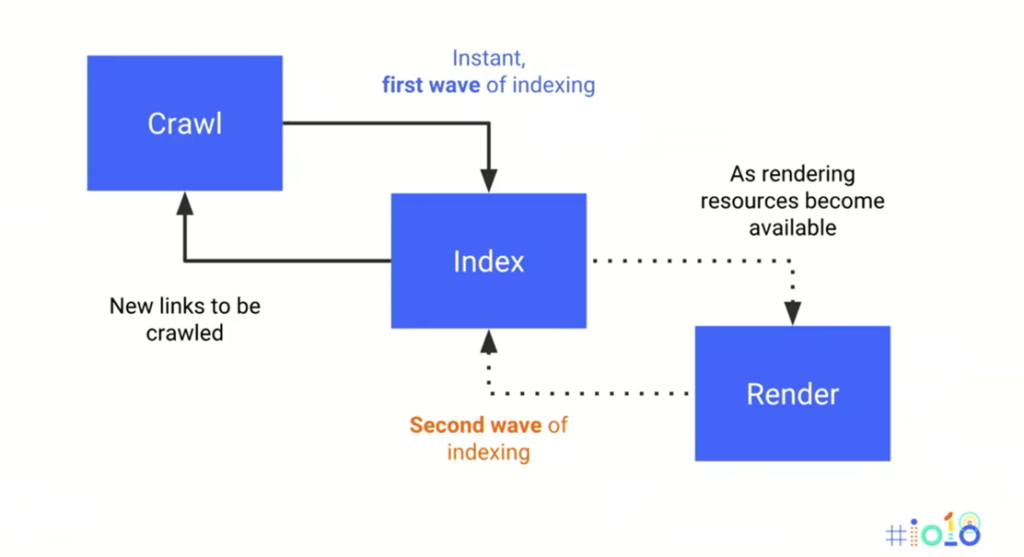
Bonne question ! L'exploration du web est essentielle pour les moteurs de recherche comme Google, Bing ou Yahoo! Ils utilisent des crawlers pour découvrir et indexer le contenu de toutes les pages web. Sans le crawling, impossible pour eux de savoir ce qui se trouve sur internet et donc, impossible de te donner les résultats de recherche que tu attends quand tu tapes une requête ! Impensable, n'est-ce pas ?
Alors, comment ça marche en pratique ? Le crawler commence par une liste de pages web connues (les seeds, les graines). Il visite ces pages, extrait tous les liens qu'il y trouve, puis visite les pages liées. Et ainsi de suite. C'est un cycle sans fin, une quête permanente de nouvelles informations.

Le processus est automatisé, bien sûr. Imagine le travail que ça représenterait de faire ça à la main ! Les crawlers sont programmés pour suivre des règles et des algorithmes complexes, afin d'optimiser leur exploration et de ne pas surcharger les serveurs web. Ils doivent être gentils, ces petits robots !
D'ailleurs, sais-tu que les propriétaires de sites web peuvent influencer le comportement des crawlers ? Oui, grâce à un fichier appelé robots.txt. Ce fichier indique aux crawlers quelles parties du site ils peuvent explorer et lesquelles ils doivent ignorer. C'est comme mettre des panneaux "ne pas déranger" sur certaines portes.
Le Crawling : Plus qu'une simple exploration
Le crawling ne sert pas uniquement à indexer les pages web pour les moteurs de recherche. Il est aussi utilisé pour d'autres applications, comme :
- La surveillance du web : pour détecter les mentions d'une marque, d'un produit ou d'une personne.
- L'analyse de la concurrence : pour surveiller les prix, les promotions et les nouvelles offres des concurrents.
- La collecte de données : pour extraire des informations spécifiques, comme les adresses e-mail, les numéros de téléphone ou les données de produits.
En résumé, l'exploration du web, ou le crawl, est un processus fondamental pour le fonctionnement du web tel que nous le connaissons. C'est le moteur qui permet aux moteurs de recherche de trouver et d'indexer l'information, et qui ouvre la voie à une multitude d'autres applications. Pas mal, hein ?
Alors, la prochaine fois que tu feras une recherche sur Google, pense à ces petits robots infatigables qui parcourent le web sans relâche pour te fournir les résultats les plus pertinents. C'est un peu grâce à eux si tu trouves cette recette de gâteau au chocolat parfaite ! Et maintenant, si on prenait une autre tasse de café ? On a encore plein de choses à découvrir ensemble ! N'est-ce pas merveilleux ?